Você aí, tem medo de usar o git? O máximo que faz é commitar e subir? Os outros comandos te assustam? Não se preocupe, você não está sozinho!
O Git pode parecer intimidante no início, mas uma vez que você entenda o básico, ele se torna uma ferramenta poderosa e indispensável para qualquer dev!

Neste artigo, vou explicar alguns comandos úteis e quando utilizá-los.
git stash
O comando git stash permite que você salve temporariamente as mudanças que você fez no seu código, sem precisar commitar tudo de uma vez.
É como se você estivesse colocando suas alterações em um esconderijo temporário, para que possa trabalhar em outras coisas sem se preocupar em perder o trabalho que já fez. Quando você estiver pronto para voltar a trabalhar nas alterações, basta abrir o esconderijo e recuperar o que estava dentro dele.
Os comandos git stash pop e git stash apply são usados para aplicar as alterações armazenadas em um stash ao seu diretório de trabalho.
A diferença entre eles é o que acontece com o stash após a aplicação das alterações:
-
git stash applyEste comando aplica as alterações do stash mais recente (ou especificado) ao seu diretório de trabalho, mas deixa esse stash na lista de stashes para possível reutilização -
git stash popEste comando aplica as alterações do stash mais recente (ou especificado) ao seu diretório de trabalho e remove esse stash da lista de stashes. Porém, se houver conflitos após ogit stash pop, ele não removerá o stash, fazendo com que se comporte exatamente como ogit stash apply
Então basicamente, git stash pop é git stash apply && git stash drop
Mas lembre-se, se houver conflitos durante a aplicação do stash, ambos os comandos irão desencadear o modo de resolução de conflitos de mesclagem e nenhum deles se livrará do stash
Para visualizar todos os stashes, use o comando git stash list
Para dar um nome ao stash, use o comando git stash save nome-do-seu-stash
git mv
O comando git mv é usado para renomear ou mover arquivos sem perder o histórico do git. Ele tem a seguinte sintaxe:
git mv [origem] [destino]
origemé o nome do arquivo ou diretório que você deseja renomear ou mover.destinoé o novo nome ou caminho do arquivo ou diretório.
Por exemplo, para renomear um arquivo chamado index.html para home.html:
git mv index.html home.html
Para mover um arquivo chamado index.html para o diretório public_html:
git mv index.html public_html/
Para renomear um diretório chamado scripts para scripts_new:
git mv scripts scripts_new
Para mover um diretório chamado scripts para o diretório src:
git mv scripts src/
O comando git mv rastreia as alterações nos arquivos e diretórios que você renomeia ou move. Isso significa que você pode reverter essas alterações se precisar.
Se você renomear um arquivo chamado index.html para home.html, e depois decidir que não quer mais a renomeação, você pode reverter a alt: git reset HEAD index.html
Isso restaurará o arquivo index.html para o seu nome original.
git amend
Com o git amend, você pode fazer alterações em um commit anterior sem precisar criar um novo commit.
-
git commit --amend --no-edit: altera o último commit que você fez. Isso é útil quando você percebe que esqueceu de adicionar um arquivo ou precisa corrigir um erro no commit anterior. O parâmetro--no-editsignifica que você não precisa editar a mensagem do commit anterior. Se você quiser editar a mensagem, basta remover esse parâmetro. -
git commit -m 'mensagem alterada' --amend: altera a mensagem do último commit que você fez. Isso é útil quando você percebe que a mensagem do commit anterior não está clara o suficiente ou precisa ser mais específica.
git fetch
O comando git fetch é usado para buscar as atualizações mais recentes de um repositório remoto e atualizar o seu repositório local com essas mudanças.
É como se você estivesse buscando as últimas notícias de um jornal para se atualizar, mas sem necessariamente ler todas as notícias. O git fetch baixa as mudanças do repositório remoto, mas não as integra automaticamente ao seu repositório local. Para isso, você precisará usar outro comando, como o git merge.
Por exemplo, imagine que você tenha um repositório remoto chamado projeto-1-origin e um repositório local chamado projeto-2. Para manter os dois repositórios sincronizados, terá que adicionar o projeto-1-origin como um "remote" no seu repositório local. Isso pode ser feito com o comando:
git remote add repo1 <url-do-repositorio-1>
O nome repo1 é apenas uma referência para o repositório remoto no seu repositório local. Geralmente, é comum usar "origin" como nome para o repositório remoto principal, mas você pode escolher qualquer nome que faça sentido para o seu projeto.
Agora, para sincronizar com o repositório remoto, buscando todas as branches e atualizações,: git fetch repo1
Em seguida, você pode mesclar a branch principal (ou qualquer outra branch que você queira) do repositório 1 para a branch atual do repositório:
# Integra as mudanças baixadas ao seu repositório local
git merge repo1/main
Resolva quaisquer conflitos de mesclagem que possam ocorrer e por fim, faça o commit e o push das alterações para o repositório 2
git rebase
O comando git rebase é usado para mover ou combinar uma sequência de commits para um novo commit base, reescrevendo o histórico do projeto. É um dos comandos mais poderosos, que te permite alterar a ordem, commits, além de ajudar a manter um histórico de commits mais limpo e organizado.
É como se você podesse pegar um conjunto de cartas de baralho e reoganizá-las da maneira que quiser, criando uma nova sequ�ência de cartaas que mais faz sentido para você.
O rebase é uma alternativa ao comando git merge, que também é usado para integrar as mudanças de um branch para outro. A principal diferença entre o rebase e o merge é que o rebase move os commits de um branch para outro, enquanto o merge cria um novo commit que combina as mudanças de ambas branches.
Isso significa que o rebase pode ser usado para criar um histórico de commits mais linear e fácil de entender, enquanto o merge pode ser usado para manter um histórico de commits mais completo e preciso.
Você pode usar o comando git rebase para:
- Reorganizar commits
- Editar mensagens de commit
- Alterar nome da pessoa do commit
- Dividir um commit em vários commits menores
- Combinas vários commits em um único commit
Para editar a mensagem dos últimos 10 commits de uma branch. Faça da seguinte forma com o comando:
git rebase -i HEAD~10
- Isso abrirá um editor de texto com uma lista dos últimos 10 commits.
- Substitua pick porreword na frente de cada commit que você deseja editar
- Salve e feche o editor
- Isso abrirá outro editor de texto que permitirá que você edite a mensagem de commit do commit selecionado
- Salve e feche o editor novamente e o Git irá reescrever o histórico de commits com as novas mensagens de commit
Se o seu editor de texto não estiver abrindo como esperado, execute o seguinte comando: git config --global core.editor "code --wait"
Isso define o VS Code como o editor padrão para o Git. Ou seja, sempre que o Git precisar que você insira uma mensagem de commit ou faça outras edições de texto, ele abrirá automaticamente esses arquivos no VS Code. A flag--wait é importante porque instrui o Git a aguardar at
Em alguns casos, acontece da pessoa não alterar o nome de configuração global do Git e commitar com o nome do outro colega, commitar sem nome, ou algum erro em específico.
e para corrigir isso, podemos alterar o nome da pessoa que fez os últimos 10 commits em uma branch,da seguinte forma:
git rebase -i HEAD~10
- Isso abrirá um editor de texto com uma lista dos últimos 10 commits.
- Substitua pick por edit na frente de cada commit que você deseja alterar
- Salve e feche o editor
- Para cada commit, os seguintes comandos:
git commit --amend --author="Novo Nome <novoemail@email.com>"
git rebase --continue
Depois de alterar todos os commits, você precisará forçar o push para o repositório remoto se já tiver feito o push desses commits:
git push origin +nome-da-sua-branch
O sinal de mais (+) antes do nome da branch no comando git push é o que permite o “push forçado”. Isso significa que o Git substituirá a branch remota mesmo que a sua versão local esteja desatualizada, o que é necessário quando você reescreve o histórico de commits como fez aqui.
Lembre-se de que isso pode causar problemas para qualquer pessoa que já tenha clonado ou bifurcado seu repositório, então use com cuidado!!
Conclusão
Viu só como não é um bicho de sete cabeças? O Git possui muitos comandos que facilitam o nosso dia a dia para resolver alguns problemas relacionados. Espero que esse artigo tenha te ajudado a entender alguns comandos. Lembre-se que a prática leva à perfeição!
Em breve, irei escrever a parte 2 com mais alguns comandos. O Git possui inúmeros deles e dicas que podem facilitar ainda mais o seu trabalho. Até a próxima!

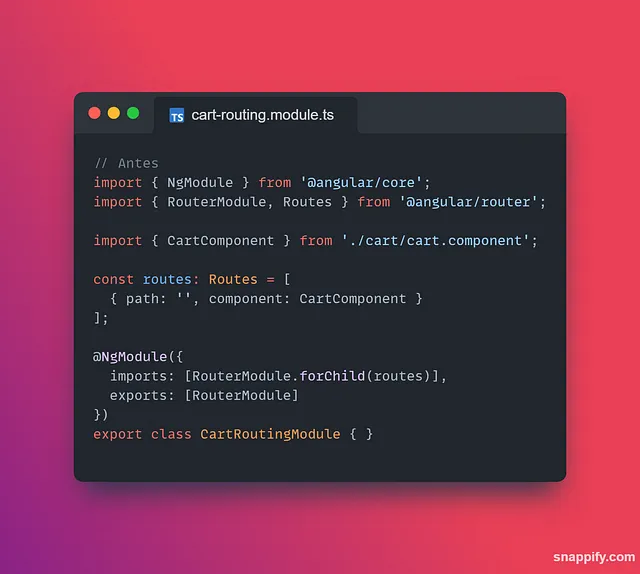
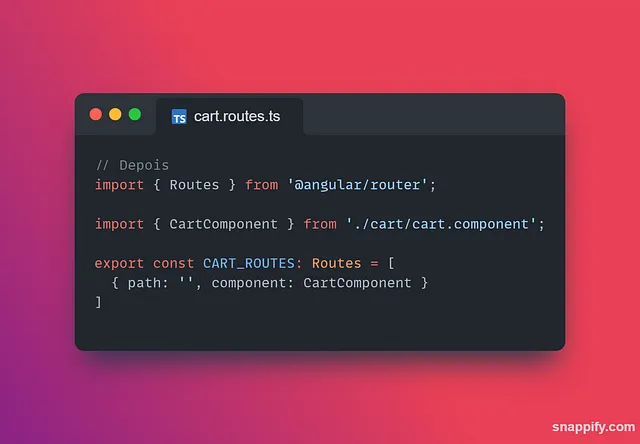
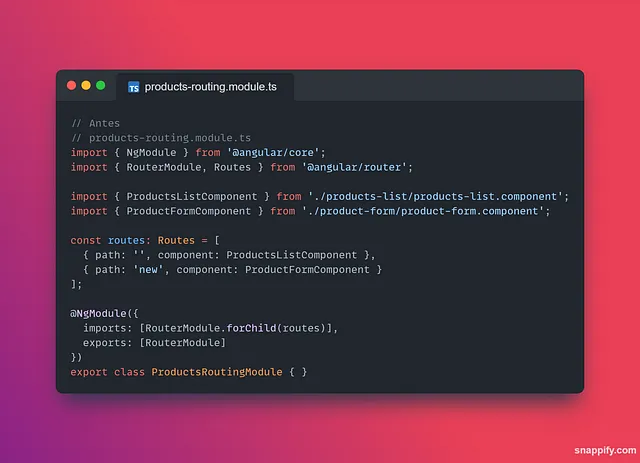
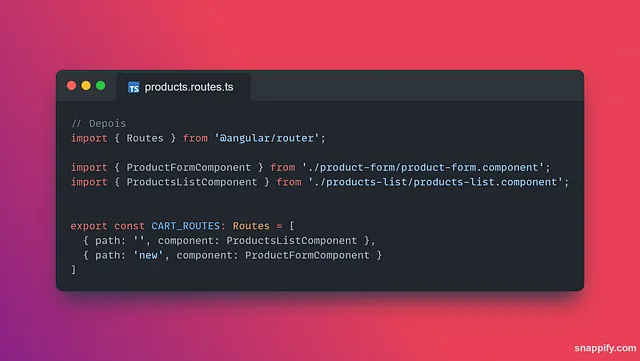


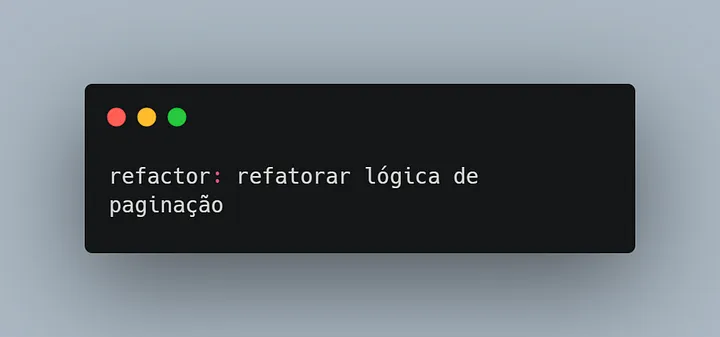
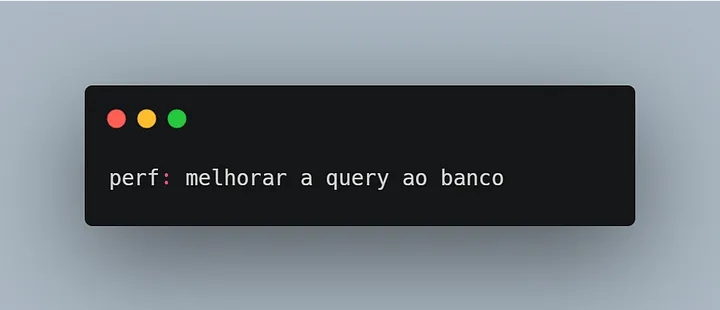
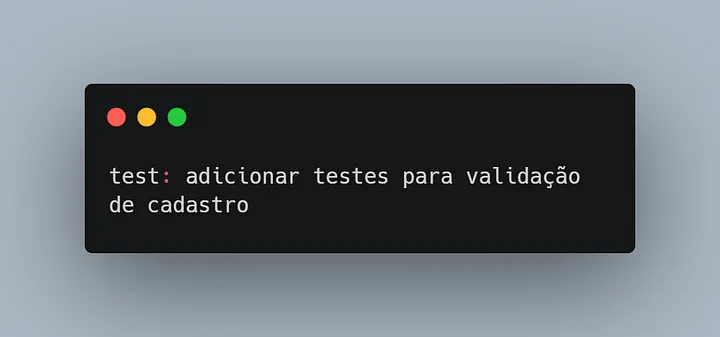 O tipo “test” é usado para commitar alterações durante a cobertura de testes, ou adicionar novos testes ao código.
O tipo “test” é usado para commitar alterações durante a cobertura de testes, ou adicionar novos testes ao código.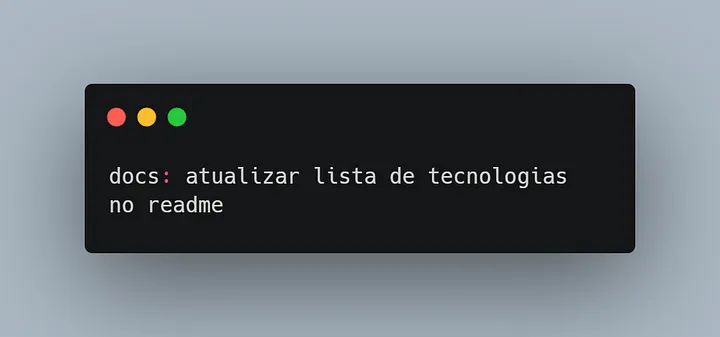 O tipo “docs” é usado para commitar alterações em documentação do código.
O tipo “docs” é usado para commitar alterações em documentação do código. O tipo “chore” é usado para commitar mudanças que não são diretamente relacionadas ao desenvolvimento de novas funcionalidades ou correções de bugs.
O tipo “chore” é usado para commitar mudanças que não são diretamente relacionadas ao desenvolvimento de novas funcionalidades ou correções de bugs.